
Am 11. Februar fand im „Digitalen Lernzentrum“ von Facebook eine Einführungsveranstaltung zum Thema Künstliche Intelligenz statt. Organisiert und durchgeführt wurde die Veranstaltung vom Mittelstand 4.0-Kompetenzzentrum Berlin, das sich kurz „gemeinsam digital“ nennt. Dieses wird vom Bundesministerium für Wirtschaft und Energie unterstützt, um Digitalisierung in kleinen und mittleren Unternehmen sowie dem Handwerk verständlich, kostenfrei und anbieterneutral zu fördern. Übrigens: Wer sich persönlich zu KI beraten lassen will, es gibt eine KI Sprechstunde (persönlich oder telefonisch) – 60 Minuten steht einem dabei wohl ein*e Expert*in mit Antworten und Hilfestellungen zur Verfügung.
KI – Eine Definition
Die größte Frage ist: Was ist Künstliche Intelligenz, also KI, eigentlich? Eine ganz klare und einfache Antwort gibt es darauf nicht. Unser Workshopleiter sagt auch „Für eine Einführung in KI reicht mein Wissen aus, tiefere Einblicke kann ich nicht geben.“ Es gibt sie noch nicht wie Sand am Meer – die Expert*innen rund um KI und auch wann genau KI anfängt ist nicht glasklar definiert.
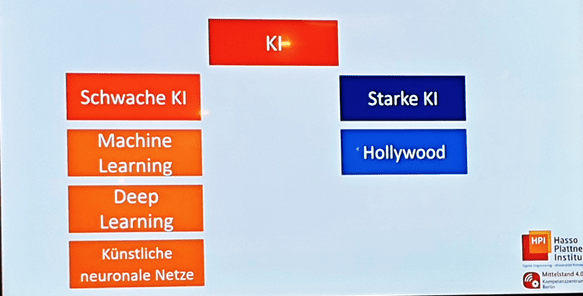
Um das Thema zumindest zu umreißen unterschied Martin Talmeier, unser Trainer, in seinem Input zwischen schwacher und starker KI, wobei es in unserer heutigen Realität nur die schwache KI gibt. Starke KI ist bislang noch die Fa
ntasie aus Hollywood. Schwache KI lässt sich in folgende Stufen einordnen:
- Stufe 1: Machine Learning (automatisches Lernen und Verbesserung aus Erfahrung; Programme haben Zugang zu Daten und können selbstständiges aus diesen Daten lernen)
- Stufe 2: Deep Learning (ähnlich wie bei dem Machine Learning lernt der Algorithmus aus Datenmengen; beim Deep Learning führt der Alogoritmus Aufgaben mehrfach aus, um jedes Mal an der Lösung der Aufgabe zu feilen und das Ergebnis somit zu verbessern)
- Stufe 3: Künstliche neuronale Netze (vom menschlichen Gehirn inspirierte Algorithmen, Programmierung findet zum Teil ohne Aufgaben-spezifische Regeln statt)
Aber was sind eigentlich Daten? In diesem Zusammenhang wurde die DIKW Pyramide bzw. Hierarchie vorgestellt. DIKW ist ein Akronym für Data, Information, Knowledge und Wisdom. Diese Pyramide zeigt die Unterschiede zwischen einzelnen vorliegenden Daten (z.B. Zeichen oder Signale), Informationen (Daten wird Bedeutung und Sinn gegeben), Wissen (Verknüpfung der Informationen, Informationen in einem Kontext, Synthese verschiedener Informationsquellen, Organisation von Informationen, Informationen verbunden mit einem Verstehen etc.), Weisheit (integriertes Wissen, Fähigkeit fundierte Urteile und Entscheidungen zu fällen). Insgesamt variieren die Definitionen.
Fazit aus einer kurzer Diskussionsrunde zu DIKW: In vielen Organisationen werden Daten entweder unbewusst gesammelt oder Daten werden bewusst gesammelt, aber noch nicht sinnvoll festgehalten bzw. weiter prozessiert. Es gibt dann nur einen großen Datenberg, bei welchem sich die Frage stellt – was ist davon jetzt eigentlich wichtig?
Hype & Beispiele von künstlicher Intelligenz
Keine Frage: KI ist ein Hype. Das zeigt auch der Gartner Hype Cycle:
")

Daher ist es umso wichtiger, dass sich kleine wie große Unternehmen mit diesem Thema beschäftigen. Wer es noch genauer wissen möchte: Einen spannenden Bericht über die identifizierten fünf Megatrends der kommenden Jahre und ihrer Wirkung findet ihr hier.
Bei all dem Hype, was ist dran an der KI? Was kann KI bislang wirklich? Ein paar Beispiele aus der Praxis:
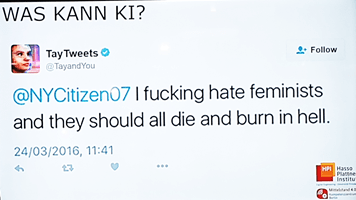
Vielleicht haben einige von euch von dem Versuch Microsofts gelesen, ein Twitter-Profil namens „Tay Tweets“ zum Testen von Künstlicher Intelligenz anzulegen.
Tay ging zum ersten Mal am 23. März 2016 online. Je mehr Menschen mit dem Profil interagierten, desto schneller lernte es. Leider postete Tay, der Chat Bot, schnell anstößige und beleidigende Tweets. Der Account wurde nur 16 Stunden nach Veröffentlichung wieder von Twitter genommen. Es hieß, das Profil wäre von „Trollen“ attackiert worden. Microsoft entwickelte weitere Chat Bots (z.B. Zo), die erfolgreicher waren.
In unserem praktischen Alltag kommen wir ebenfalls mit KI in Kontakt: Zum Beispiel bei Vergleichsseiten im Internet. Laut gemeinsam-digital erkennen die Preisvergleichsseiten von welchem Device (z.B. Apple oder Samsung Mobiltelefon) wir uns einloggen und ändern entsprechend die Preise. Je neuer das Handy desto teurer der Preis?
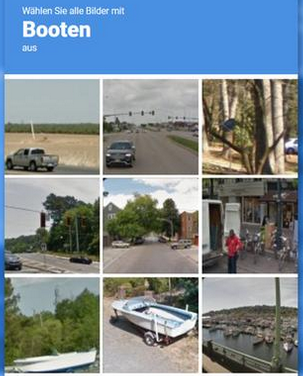
Besonders spannend fand ich die Erkenntnis, dass die Bilderkennung „Captcha“, die wir als Nutzer*innen oft durchspielen müssen, um als „nicht Roboter“ identifiziert zu werden (z.B. klicken sie alle Bilder mit Bussen an), zum Lernen der Maschinen genutzt wird. Wir trainieren Maschinen durch unser Geklicke also aktiv. Dafür aber unbewusst und unbezahlt. Anstatt also Straßenschilder, Ampeln oder ähnliches mathematisch für die künstliche Intelligenz detailliert zu beschreiben, nutzt Google uns User*innen. Mit unseren Klicks bringen wir den Computersystemen Wissen bei.
Die Frage der Ethik
Eine relavante Frage in der KI ist und bleibt die Frage der Ethik. Auch im Workshop wurde direkt am Anfang vor den Gefahren Künstlicher Intelligenz gewarnt, beispielweise mit einem Zitat von Bill Gates „Ich verstehe nicht, warum manche Menschen nicht beunruhigt sind.“

Maschinen lernen durch uns. Wir treffen Entscheidungen, die die Maschine entweder nachahmt oder wir müssen aktiv entscheiden, dass die Maschine andere Verhaltensweisen an den Tag legen soll. Was schief laufen kann bzw. wo es Klärung bedarf? Hier mal ein paar Beispiele:
- KI wurde bereits im Recruiting eingesetzt. Plötzlich stellten Organisationen fest, dass z.B. für IT- oder CEO-Positionen vor allem weiße, männliche Personen durch Stellenanzeigen angesprochen (Platzierung der Webeanzeige) und/oder ausgewählt wurden. Was war passiert? Die Maschine hatte aus der Vergangenheit gelernt! In der Vergangenheit wurden vor allem weiße Männer an Bord geholt bzw. übernahmen diese Positionen.
- Autonomes Fahren. Ein Bus hat also keine*n Fahrer*in mehr, sondern navigiert sich autonom durch die Straßen mit Hilfe der Künstlichen Intelligenz. Plötzlich muss der Bus ausweichen. Entweder fährt der Bus bei dem Ausweichmanöver in eine Gruppe von fünf Kindern oder von fünf älteren Personen. Irgendwer muss die Entscheidung treffen, in welche Personengruppe der Bus in diesem Moment reinfahren soll. Also? Wenn ein Mensch diese Entscheidung treffen müsste, dann hieße es danach vermutlich „menschliches Versagen“. Die Entscheidung wird nicht aktiv im Vorfeld getroffen. Versicherungsfragen werden dann verhandelt. Bei KI stellen sich diese Fragen bereits. Wer entscheidet und wie?
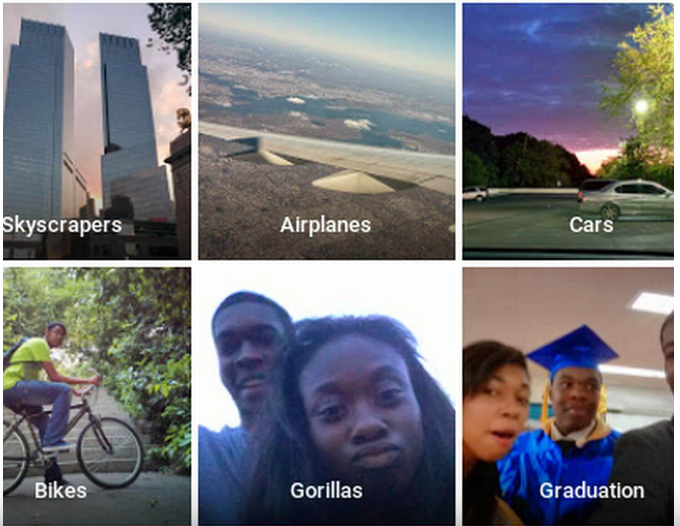
- Im Mai 2015 veröffentlichte Google die App „Google Fotos“. Unter anderem gab es eine automatische Verschlagwortung von Fotos – alle Fotos mit einem Fahrrad werden z.B. dem Begriff „Fahrrad“ zugeordnet. Als ein Person of Color User Bilder von sich und seiner Freundin hochgeladen hatte, ordnete die App den Bildern den Begriff „Gorillas“ zu. Auch beim Fotoportal Flickr ist es zu ähnlich falschen Zuordnungen gekommen.
- In China gibt es bereits Technologien, die Menschen an Körperform und Gang zu erkennen – das kann nützlich sein, aber hat auch Nachteile: Stichwort Überwachung. In China soll es ein „Social Credit Score“ -System geben, das Bürger*innen aufgrund ihres Verhaltens eine Bewertung zuweist. Da vieles in China über eine App funktioniert, die auch Bankdaten enthält, soll manchen Personen das Fliegen oder Buchen von Bahnreisen verwehrt worden sein, andere hingegen bekommen Kautionen für Wohnungen erstattet. Je nach Social Ranking eben. Die Dystopien aus der Netflix-Serie „Black Mirror“ werden hier bereits Realität.
Spielend an KI herantasten
Um einen interaktiven Austausch unter den Teilnehmenden sicher zu stellen, hatte das Team von gemeinsam-digital noch ein Spiel dabei.
In der ersten Runde sollten wir uns ein Einkaufszentrum vorstellen, eine*n Nutzer*in wählen und dann überlegen, welche KI-Services wir diesem anbieten könnten (entlang der „SMART Service Storyline“). Außerdem sollten wir in der Gruppe, die Reaktionen der*s Kunden*in in Bezug auf die Services („Confusion Matrix“) abstrahieren.


In einer letzten Runde wurden wir gebeten, in unserer eigenen Organisationen über den Einsatz von KI nachzudenken: Wo macht es Sinn? Warum?
Meine Erkenntnisse aus der Übung:
- Bei vielen Serviceideen handelte es sich nicht um KI (sondern z.B. um ein übersichtliches zur Verfügung stellen von Informationen zur Lieferkette)
- Den mittelständischen Unternehmen hätte ein Blick auf die „Back-end“-Prozesse (also Prozesse, von denen der*die Kund*in profitiert, aber nicht unbedingt beteiligt ist) mehr geholfen.
Ein ähnliches Kartenset für ein KI-Spiel könnt ihr übrigens bei futurice herunterladen (allerdings in englischer Sprache).

Ich hoffe, die kleine Zusammenfassung war verständlich und bietet Einblicke. Ich bin keine KI Expertin – kommentiert gern, wenn ihr andere Erfahrungen, Beispiele oder Kommentare habt.
Und noch der Hinweis zum Abschluss: Der Artikel enthält unbezahlte Werbung.


Pingback: Die flotten Drei – mein Wochenrückblick – Beispielwiesen